Amazon Resolves 15-Hour AWS Cloud Service Outage
Amazon Web Services (AWS), the leading cloud service provider, has successfully resolved a significant outage that lasted approximately 15 hours on Monday. This incident underscored the critical role AWS plays in the functioning of numerous online platforms and services worldwide.
The company announced via its service health dashboard that all services returned to normal operations by around 6 p.m. New York time. AWS is responsible for a substantial portion of the internet’s infrastructure, holding about one-third of the cloud market share. During the outage, users experienced disruptions across various sectors, including finance, entertainment, and food services.
Impact of the Outage
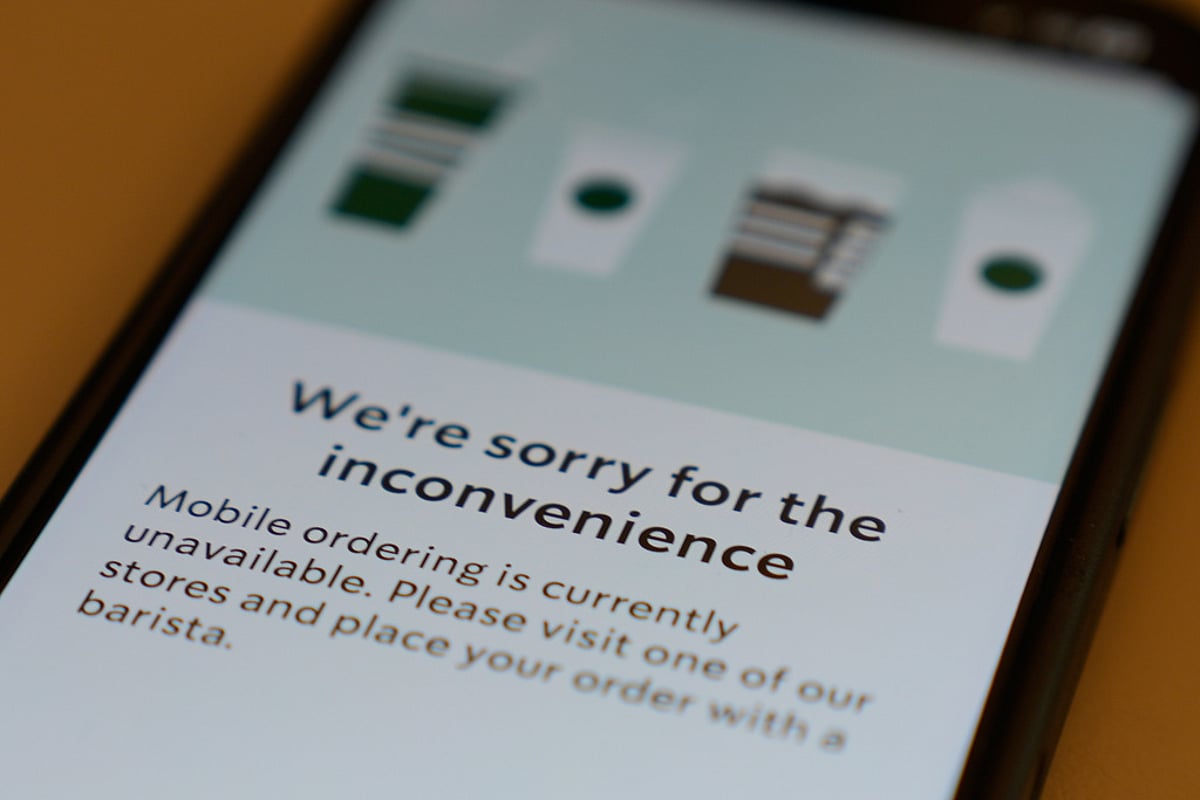
The outage affected a wide range of services, with Downdetector reporting issues at hundreds of websites. Notable companies impacted included financial services like Venmo and Robinhood, streaming services such as Apple Music and TV, and software platforms like Zoom and Salesforce. Even Amazon’s own services, including Alexa and Ring, were not spared from the disruptions.
Corey Quinn, a cloud economist at Duckbill, remarked that this outage could be one of the most severe AWS has faced since a major incident in December 2021. He noted the increasing interconnectedness of technology systems, raising concerns about the potential for widespread disruptions when a single provider encounters issues.
Cause of the Disruption
AWS identified that a malfunction in a digital directory for a key database service triggered the cascading failures. This malfunction prevented software reliant on the database from retrieving necessary information, primarily affecting operations on the US East Coast, which houses AWS’s largest data center cluster. As engineers worked to rectify the issue, they discovered additional subsystems, including those needed for launching new servers, were also impacted.
While major tech companies typically resolve glitches quickly, the interconnected nature of modern technology means that problems at one provider can lead to significant repercussions across the global economy. For instance, a faulty software update from cybersecurity firm CrowdStrike last year caused widespread flight disruptions and system failures, resulting in billions of dollars in damages.
Historical Context
This incident is reminiscent of AWS’s previous outages, including one in December 2021 that disrupted services for various industries, from entertainment to retail. Following that outage, Amazon explained that an automated program intended to enhance network reliability inadvertently caused many systems to behave erratically, leading to a surge in activity that overwhelmed AWS networks.
Looking Ahead
As AWS continues to recover from this incident, the company is likely to evaluate its systems and protocols to prevent similar occurrences in the future. The reliance on cloud services by businesses and consumers alike emphasizes the need for robust infrastructure and contingency plans.
FAQs
What caused the AWS outage?
The outage was primarily caused by a malfunction in a digital directory for a key database service, which led to cascading failures across various systems.
How long did the outage last?
The outage lasted for approximately 15 hours, with services returning to normal operations by around 6 p.m. New York time.
What types of services were affected?
Numerous services were impacted, including financial platforms like Venmo and Robinhood, streaming services such as Apple Music, and software applications like Zoom and Salesforce.
Conclusion
The recent AWS outage highlights the vulnerabilities inherent in our increasingly interconnected digital landscape. As Amazon works to enhance its infrastructure and prevent future disruptions, users and businesses alike must remain vigilant and prepared for potential service interruptions.
The incident has reignited discussions about the resilience of cloud infrastructure and the potential risks associated with over-reliance on a single provider. As businesses increasingly migrate their operations to the cloud, the implications of such outages can extend beyond immediate service disruptions, potentially affecting revenue streams and customer trust.
In light of this outage, experts may call for a reevaluation of disaster recovery strategies and the diversification of cloud service providers to mitigate risks. Companies that depend heavily on AWS might consider implementing multi-cloud strategies, which involve utilizing services from multiple cloud providers to enhance reliability and reduce the impact of any single point of failure.
Furthermore, regulatory scrutiny may increase as governments and industry bodies assess the implications of such outages on critical infrastructure. The need for transparency in reporting outages and their causes could become a focal point in discussions about cloud service governance and accountability.
Also Read:
AWS Restores Cloud Services After Major Outage